[Deep Dive] How do Large Language Models work?
Breaking down what ChatGPT and others are doing under the hood

This is a deep dive post, exclusively for paid subscribers. The last one covered frontends and backends.
Large Language Models (LLMs) like ChatGPT, the new “Sydney” mode in Bing (which still exists apparently), and Google’s Bard have completely taken over the news cycles. I’ll leave the speculation on whose jobs these are going to steal for other publications; this post is going to dive into how these models actually work, from where they get their data to the math (well, the basics you need to know) that allows them to generate such weirdly “real” text.
💡Interested in more AI and Machine Learning related content like this? Or would you rather me stick to traditional software engineering? Let me know in the comments.
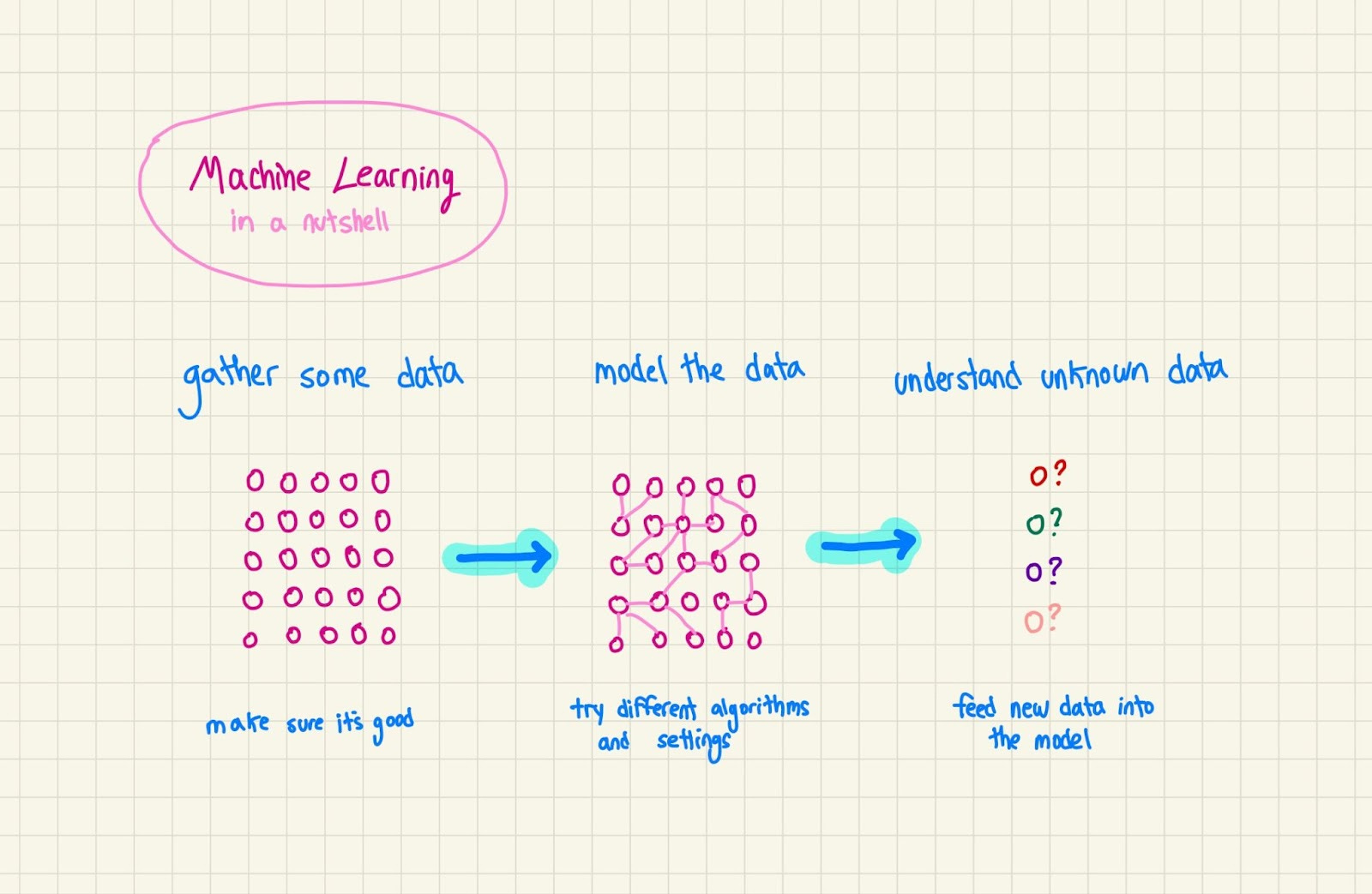
Machine learning 101, a crash course
LLMs are a type of Machine Learning model like any other. So to understand how they work, we need to first understand how ML works in general. Disclaimer: there are some incredible visual resources on the web that explain how Machine Learning works in more depth, and probably better than me – I’d highly recommend checking them out! This section will give you the basics in Technically style.
The simplest way to understand basic ML models is through prediction: given what I already know, what’s going to happen in a new, unknown situation? This is pretty much how your brain works. Imagine you’ve got a friend who is constantly late. You’ve got a party coming up, so your expectation is that he’s going to, shocker, be late again. You don’t know that for sure, but given that he has always been late, you figure there’s a good chance he will be this time. And if he shows up on time, you’re surprised, and you keep that new information in the back of your head; maybe next time you’ll adjust your expectations on the chance of him being late.
Your brain has millions of these models working all the time, but their actual internal mechanics are beyond our scientific understanding for now. So in the real world, we need to settle for algorithms – some crude, and some highly complex – that learn from data and extrapolate what’s going to happen in unknown situations. Models are usually trained to work for specific domains (predicting stock prices, or generating an image) but increasingly they’re becoming more general purpose.
Logistically, a Machine Learning model is sort of like an API: it takes in some inputs, and you teach it to give you some outputs. Here’s how it works:
Gather training data – you gather a bunch of data about whatever you’re trying to model
Analyze training data – you analyze that data to find patterns and nuances
Pick a model – you pick an algorithm (or a few) to learn that data and how it works
Training – you run the algorithm, it learns, and stores what it has learned
Inference – you show new data to the model, and it spits out what it thinks
You design the model’s interface – what kind of data it takes, and what kind of data it returns – to match whatever your task is.