

Technically Monthly (Issue 3, June 2025)
How AI can use websites, why Databricks acquired Neon, how AI engineers choose a database, Technically for financiers, and more.


Hello illustrious Technically readers. This is the third ever Technically Monthly, and it’s a huge one. We’ve got for you, in no particular order:
4 brand, spanking new posts on Technically 2.0, from what MCP is to why developers choose different databases
A guest AI engineer’s take on why document databases are great for building AI tools
Technically for financial services teams (VCs, asset managers, bankers and other -ers)
Technically on Youtube (!)
A new term in the Technically universe: the loss function
New on Technically
How can AI use websites?
Available free, thanks to Vercel’s sponsorship of our writing on AI this year.
For most readers, browsing the internet is something you could do in your sleep. Perhaps you already do.
And yet, for AI models, it’s actually a highly complex, nuanced task. Newer GenAI models are getting better and better at “thinking” and complex reasoning, yes; but without the ability to navigate and use websites, they’ll be pretty much useless at automating our work for us.
So how does an AI model actually use the internet?
This is the story of how Browserbase built their Open Operator viral demo using Vercel’s AI tooling (including v0 and the AI SDK).
Why’d Databricks acquire Neon?
A free Technically dispatch.
Databricks, your friendly neighborhood purveyor of “Leading Data and AI Solutions for Enterprises” recently bought a small (but beloved) database company called Neon.
Neon is a wrapper around PostgreSQL, the most popular production database in the world; their database helps people build bread and butter apps.
Meanwhile, Databricks is out there helping giant enterprises build fancy data and AI workflows…so why in LeCun’s name did they make this acquisition at all?
Why do developers choose different types of databases?
Available as a sneak peek to paid subscribers on Substack, and now in its permanent home in the Analyzing Software Companies knowledge base.
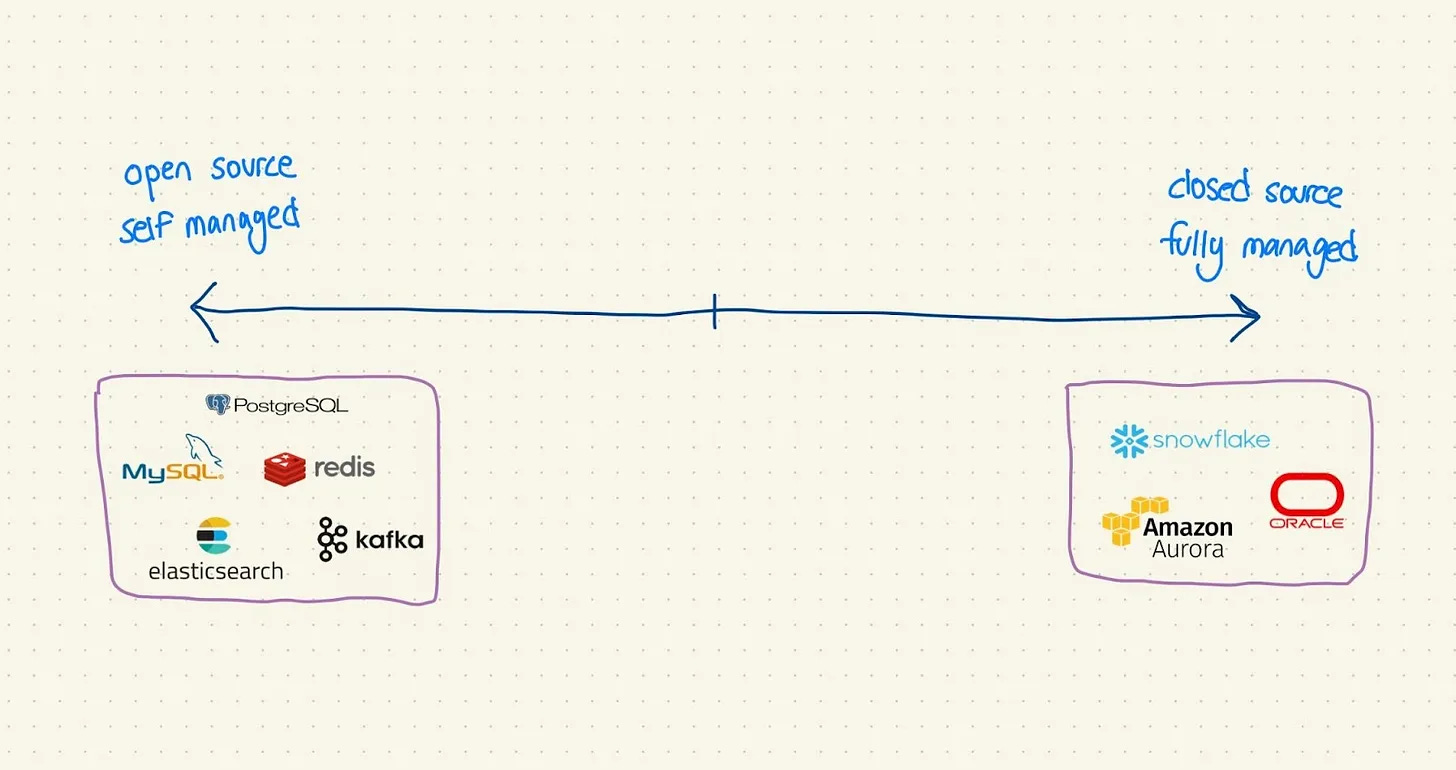
You wouldn’t think there’d be so much fanfare – and such colossal budgets – around data storage. And yet there are 6 public companies in the U.S. that have built Billion+ dollar database businesses, from $ORCL to $ESTC to $SNOW.
How should you understand the differences between all of these seemingly similar databases? What do developers actually use databases for anyway? And why would one be better than another?
What is MCP?
Available as a sneak peek to paid subscribers on Substack, and now in its permanent home in the AI, it's not that complicated knowledge base.
Following up on critically acclaimed Technically correspondent Jason Ganz’s note from May’s monthly edition, we take a deeper look at this whole MCP (Model Context Protocol) thing and why it’s suddenly everywhere on the internet.
Is this a real advancement in AI that most of us will use, or just a hype train rolling through town?
Technically for financiers
Some of Technically’s earliest subscribers were financiers – VCs, asset managers, bankers, etc. – looking to get smarter on companies and spaces they were interested in. We’re working on a special product specifically for these kinds of teams to get sharper and more technical at work.
If you’re looking to help your investment, advisory or support teams get more technical, just respond to this note, we’d love to talk.
Technically on YouTube
As of this week, we’ve started publishing short video breakdowns (~3mins) of tech news on YouTube.
Subscribe here if you’re looking for wild speculation on recent dealmaking + product announcements, with a side of mystery + classy jazz.
Notes from the field: why databases are important for AI agents
Following up on our post on why developers choose different types of databases, we invited Paul Iusztin, an AI engineer, to share his thought process on choosing databases for AI agents.
Paul is co-author of the LLM Engineer’s Handbook, and writes about building production AI systems at DecodingML.
Which database is best for building AI agents?
Every app needs a database, and AI agents, which automate stuff for us using LLMs, are no different. So, from all the databases out there, what's the best fit?
I’ve published two open-source courses on building AI agents (one on building a Second Brain AI Assistant and the other on AI NPCs in games), and have tried basically every flavor of database that you can think of (dedicated vector databases, operational databases like Postgres, NoSQL databases like MongoDB).
Here's what I've learned:
The database world for building AI agents is a mess! We’re trapped in between two worlds — the old stalwarts, like Postgres, are slow to work with, while the new vector databases can be too beta-feeling for more senior engineers.
What's actually being stored in the database?
At a higher level, all AI agents require two distinct types of data storage:
Short-term memory is the agent's current state: what conversation thread its following, temporary calculations, and the context of what it's working on right now. This changes constantly.
Long-term memory is the knowledge base: all the documents, previous conversations, and information the agent can search through to answer questions. This is your RAG (Retrieval Augmented Generation) system.
What makes AI different from regular software
These two memory types can take many forms, even within the same application, which is one of the core problems of building agentic applications. The world is highly unstructured!
AI agents deal with data that changes constantly:
The input is unpredictable. Your agent might process a PDF today, a web page tomorrow, and voice recordings next week. Each has a completely different structure.
The AI models keep changing. OpenAI releases a new model, suddenly your data format needs to adjust. Claude adds new features, and your storage requirements shift. You need to adapt quickly.
The conversations are dynamic. Unlike a typical app where users fill out forms, AI agents have flowing conversations that can go anywhere. You can't predict the data structure in advance.
You need room for experimentation. You start simple. But soon you will realise you need to add more complex algorithms, such as GraphRAG, that require entirely different database features.
How do I pick a database?
When building AI agents, you must move fast, explore, and adopt new models and algorithms—on the fly, if possible. So flexibility is a superpower. Here’s what I watch out for:
How quickly the database can adapt to changing requirements (how easily I can change database schemas)
Whether it can support multiple data types (text, images, vectors, etc)
How quickly can I get an AI agent built (without spending a lot of time integrating multiple storage systems)
How simple is it to deploy (to different cloud infrastructure)
Because of this, I've arrived as a fan of using NoSQL databases for AI agents. Why?
Traditional SQL databases were built for predictable, structured data. AI is not predictable, and that leads to spending a lot of time managing new data fields + types.
Using a standalone vector database requires dealing with integration (with an operational database of some kind for short-term memory), which I feel slows me down.
NoSQL databases can store new data structures (new fields or data types) without needing to stop and run a database migration to update the tables (as you would for a SQL database).
At some level, database choice is a matter of taste: do you pick the best tool for a specific job, and spend time integrating it? Or do you use the all-in-one option, with slightly worse features but no need for integration?
I've found that, when I build AI agents, I prefer all-in-one, just because it lets me move as fast as possible. But hey, that's me! Every AI engineer will approach this problem from a different perspective.
New in the Universe: The loss function
Let’s close with a favorite term we added to the Technically universe of technical concepts recently, the loss function:
When training a machine learning model, a loss function is something you design that tells the model when its answers are right and when they're wrong. There are a bunch of different types, some catered to specific ML tasks like image classification (does a plant have a bug on it or not) or regression (predicting a stock price), or predicting the next word in a sentence for an LLM.
As a model is trained, it predicts an answer to a question. If it's right, it gets a point. If it's wrong, it loses a point. After enough of these iterations, it starts to learn how to predict the correct answer.
Coming up next month
Thanks for joining us for Technically Monthly. Stay tuned for the next one, which will feature posts on:
How AI models “think” and reason
An overview of the market for cloud infrastructure
Developers hate this one thing (all about code reviews)
Thanks for inviting me as a guest writer. Had a great time writing this piece on NoSQL databases for agents for you!