

What’s a data science notebook?
Your data team’s favorite tool you’ve never heard of

Imagine you’re a data scientist, and you need to pull in some data about your user churn and analyze it.
Data Science notebooks – or just “code notebooks” – help you go from this blob of code:
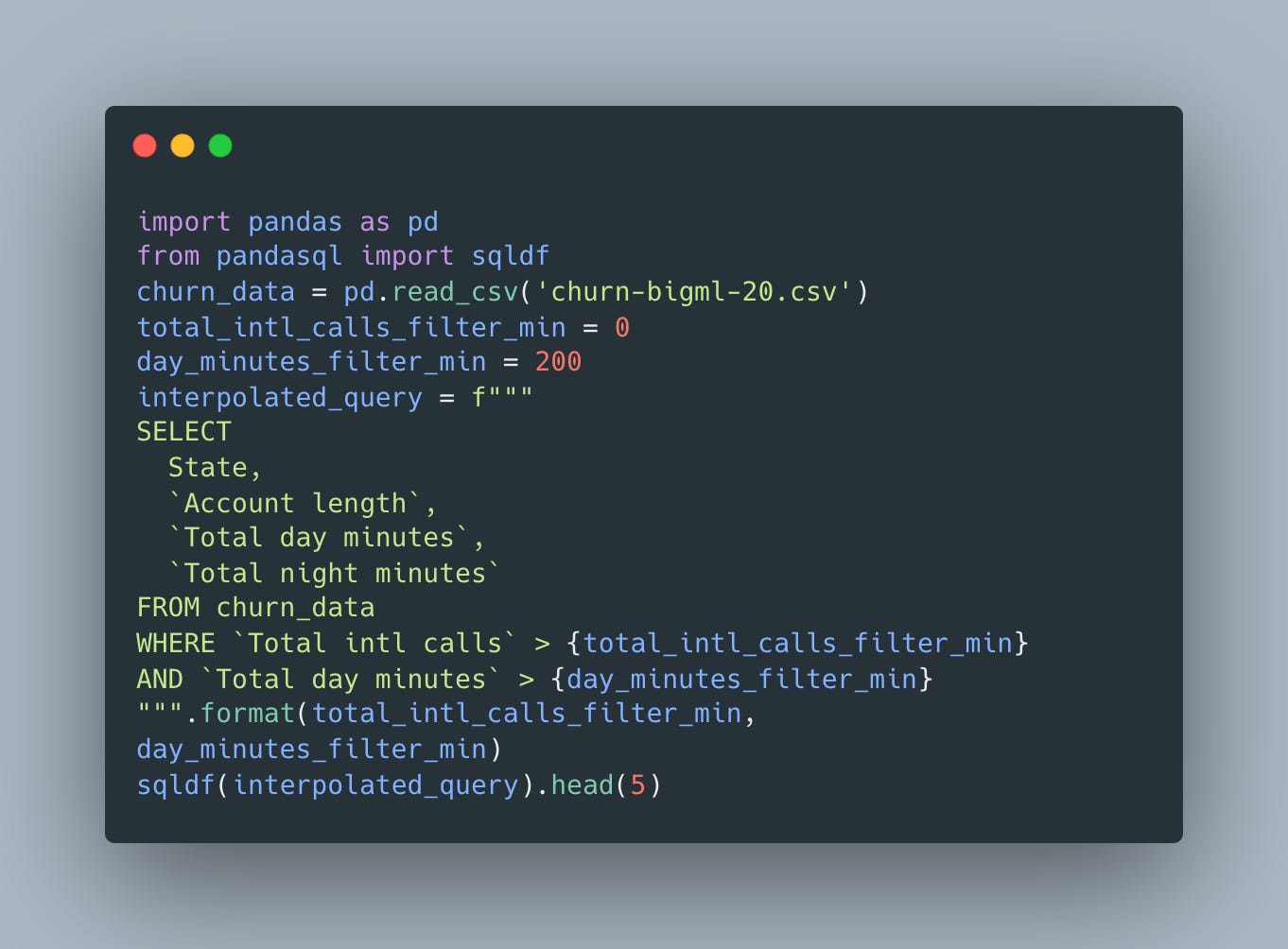
To this nicely formatted, iterative, visual set of code blocks:
