

What's an inference provider?
How the rise of open source AI models is fueling the growth of a new infrastructure category.

Hey friends, quick note for you:
There are a few sure things in life. Death, taxes, and website rebrands. We cannot help you with the first two, but…
ICYMI, we recently redesigned the technically.dev site. It should be a lot easier to read and look through now. We also brought back a crowd favorite: learning tracks. We’ve added new tracks like How AI Models Actually Work + From Spreadsheets to Databases.
And to celebrate, we’ve created a new All-access subscription there that gets you access to all learning tracks (and the entire Technically archives).
If you’re a paid Substack subscriber, you will get automatic access to this All-access subscription — just make sure to sign up on technically.dev with the same email as your Substack account.
If you’re curious to test the waters, you can start by creating a free account that lets you unlock a couple free posts a month. Enjoy!
Amidst the frenzy of AI, a new category of infrastructure vendor has emerged: The inference provider. This white-hot newish(ish) vertical is producing some pretty big headlines for a category that, as we’ll see, is often overshadowed by big AI labs like OpenAI and Anthropic. TogetherAI is in talks to raise at $7.5B, Fireworks raised at $4B last year, and Modal is in talks to raise at $2.5B – all of these are doubling and doubling every few months it would seem. NVIDIA splashed $20 billion for Groq’s inference chip technology in December, its largest acquisition to date.
So yes, inference is white hot. But what do these companies actually do? And why are they worth so much money?
Let’s dig in, shall we?
What’s inference?
AI didn’t take long to become totally ubiquitous. It answers your questions, summarizes your meeting notes, codes up your apps, and, if you’re a bad friend, writes your birthday cards. All of it, every AI product you touch, boils down to two things: training and inference.
Training is how a model learns. You take a massive amount of text and use it to produce a mathematical equation that captures patterns in language: what words tend to follow what, how ideas relate to each other, what a reasonable response to a question looks like. Models like GPT and Claude were trained on enormous amounts of text from the internet, and what emerged are systems that can produce generally fluent, useful language.
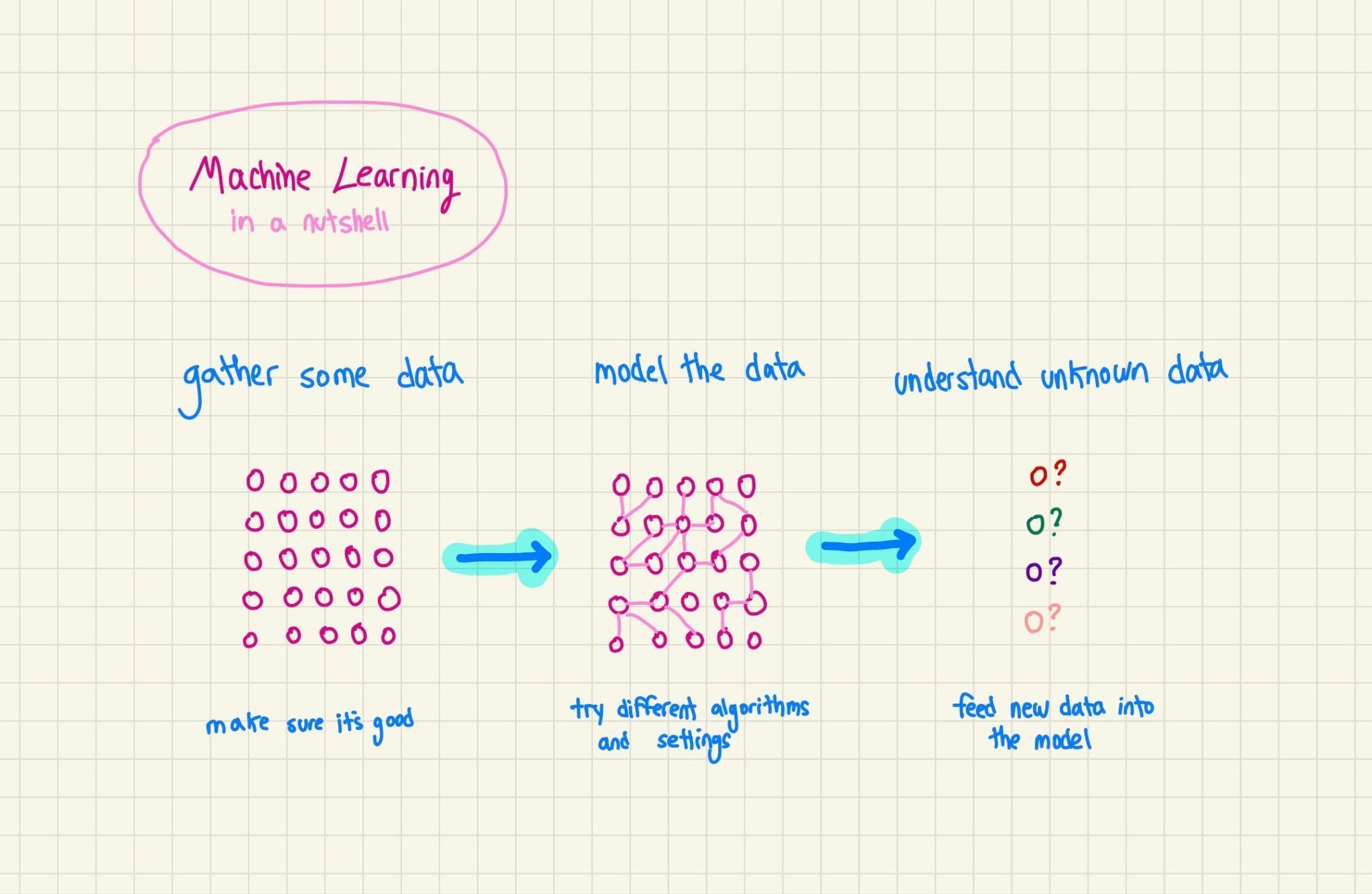
Inference is when the model actually does its job. Every time you send a message to ChatGPT and it responds, that’s inference. Every time Claude summarizes a document or an AI coding assistant autocompletes a function, that’s inference too. It’s the model taking what it learned during training and applying it to your input, in real time.
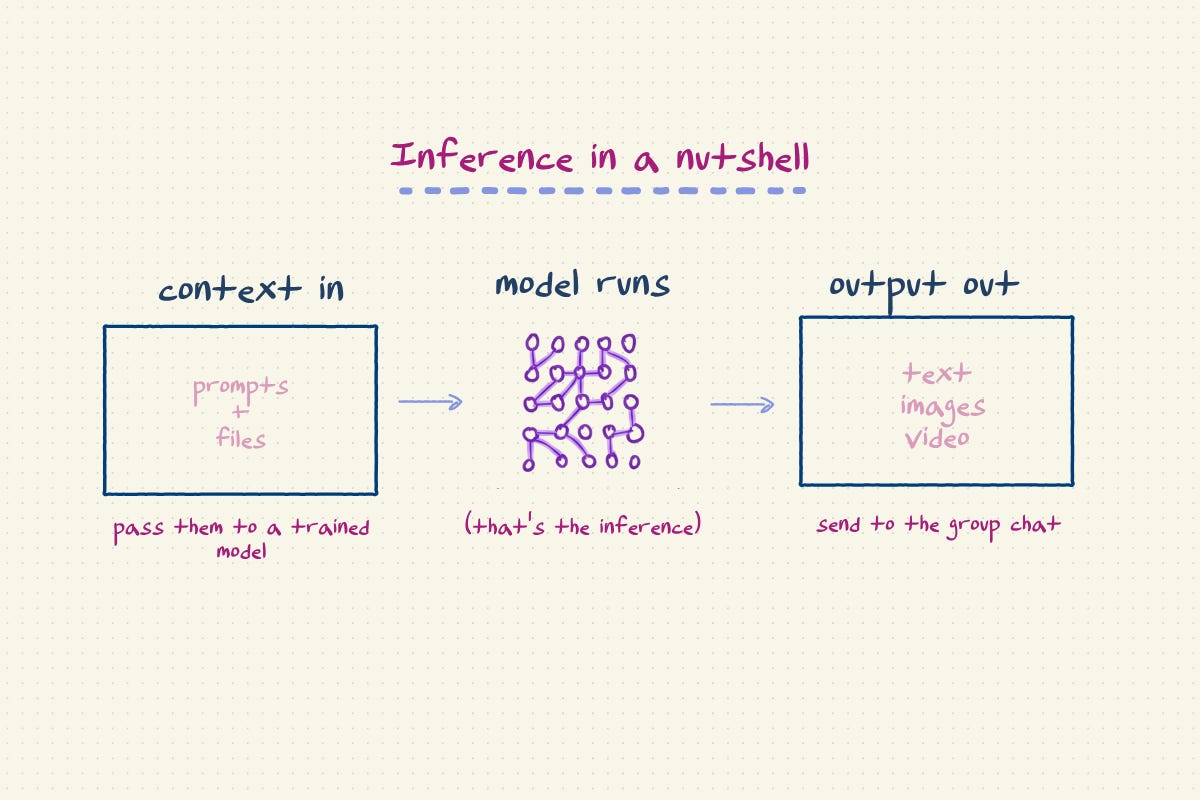
Training models has historically been the sexy part of AI, done by people in glasses, wearing turtlenecks, and holding PhDs. They are paid many dollars. Serving models, on the other hand is plumbing, but as it turns out, as every company races to add AI to their app, the plumbers are doing pretty well for themselves. Dedicated inference providers have emerged as a major force in the AI application stack, offering a convenient managed inference service for developers building AI-powered features.
In its purest and most managed form, the OpenAI and Anthropic (we’ll call them frontier labs) APIs are AI inference providers. They have both trained the models and set them up for you to use easily. You make an API call: (“write my wedding vows”) and get back an inference: (“Webster’s dictionary defines love as…”). So what are we talking about here? Why would you use something special?
Why use an inference provider?
As someone using AI or building into your app, you have two major choices. You can use a closed-source model like ChatGPT or Claude. These are proprietary models – nobody knows how they were trained – and the only way to use them is through the people who trained them, OpenAI and Anthropic. These labs (as well as other closed-source providers like Runway, Midjourney, and Google) are very good at training models, and generally their models will be the best on the planet, but also cost the most.
Then there are open source models. These are built by companies or the community, and released for all to use. The weights of these models (the key to the fancy prediction equation) and sometimes even the training code are open to the public. You can download and run them yourself or even tweak them if you’d like. The most popular ones are Llama from Meta, Qwen from Alibaba, and DeepSeek.
With open-source models, you have a choice in how you actually use them. You can self-host by spinning up your own infrastructure, loading the model weights, and managing everything yourself. Or you can instead use an inference provider: a company that hosts open-source models for you and lets you access them through an API, just like you would with a closed-source lab.
There are a few reasons a developer might use an inference provider over just calling the inference endpoints of the frontier labs directly, or running OSS models themselves.
Cost. The newest Frontier models are expensive. If your use case doesn’t actually need a state of the art model like GPT-5.4 or Claude Opus, you can run an open-weights model like LLaMA on an inference provider for a fraction of the price. For high-volume, straightforward tasks like summarization, classification, or extraction, you probably don’t need the best model on the market, and the savings add up fast.
Speed. The big frontier labs generally optimize for model capability over latency. If you’re building something where response time matters (autocomplete, real-time agents), inference providers running on optimized hardware can get you significantly faster performance.
Resilience at scale. If you’re big enough that OpenAI having an outage means your product has an outage, you have a problem. Inference providers let you route across multiple models and backends through a single API, so you’re not in hell it every time one provider has a bad day.
Native integration with your cloud. The public cloud inference provider offerings like AWS Bedrock or Google VertexAI have an advantage in the enterprise because their models and endpoints are colocated with your other infrastructure, which can matter to security and data-residency-conscious buyers. They also tend to offer the most straightforward paths to fine-tuning and customization, which is when you take a base model and train it further on your own data so it performs better for your specific use case.
All this, at least for me, actually reverses the question - why would you call the frontier labs’ APIs when the inference providers are cheaper and faster? There are at least a few reasons:
You need the latest and greatest models (remember, the inference providers are often hosting the open weights models, which are older)
Cost and/or latency are not a concern for you (congrats, happy for you)
You’re a noob and didn’t know about inference providers (me, until recently)
The inference provider spectrum
Like many software categories, there is a spectrum from:
Easy to use with fewer customizations and control for a lot of money...
…to pure infra providers that you configure to do what you want, with full control (and responsibility over) the infrastructure for less money.
Let’s take a look at that spectrum.
Most Managed: First-Party Model APIs
I already touched on this, but the AI labs themselves provide inference endpoints and, as such, are technically inference providers. You call their API, and you get a response without managing infra. It’s the simplest way to add AI to a product, and where most teams start. You get access to the newest and best models, but you also pay per call (among other things), so it’s usually the most expensive.
OpenAI: The company that started the current wave; their API format has become the de facto standard that most other providers copy.
Anthropic: Makes Claude; strong enterprise adoption, and known for handling very long documents.
Google (Gemini): Lots of models; deeply integrated into Google Cloud and Workspace suites.
Technically, the platform of the model provider isn’t the only way to access them.
Cloud Hyperscalers: Enterprise AI Platforms

 | A guest post by
|