

How to build AI products that are actually good
All about AI evals, plus how Braintrust helps companies build better AI apps.

Today is Vercel’s Ship AI conference, and I thought there’d be no better way to mark it than to give you something unprecedented for Technically: a three (yes, 3) post week.
This week we’ve bought you three (yes, 3) new pieces about the Vercel cinematic universe and why it’s so important for developers:
Tuesday: How building AI apps requires different infrastructure than web apps
Wednesday: The vibe coder’s guide to real coding — all the things you need to know to turn your vibe coded app into a reliable product
Today: How to build AI products that are actually good (all about evals)
Enjoy!
—
Imagine you’re an engineer building AI models into your product. How do you make sure they actually work?
If you’ve banged your head against the table trying to get Claude or ChatGPT to write a better email or properly summarize your test results, you already know the answer: better prompts. The more data you include and the clearer your instruction, the closer the model response is going to be to what you want. In practice, that means a bunch of back and forth between you and the model until you’re happy; it’s an iterative process that in some senses is never finished.
But if you’re a developer building AI models into your app – and they’re going to be used by tons of users around the globe – things are a little more complicated. For apps that go big, you could have millions of users interacting with these models every day. At this kind of scale, you can’t just prompt, hope for the best, and then wait to see what happens – you risk weird, incorrect, or downright dangerous responses to your users.

This is where evals come in. They help companies continuously improve the performance of the models in their products via a feedback loop of monitoring and scoring. And the best and easiest way to run them is via Braintrust, which helps teams measure, evaluate, and improve AI in production. They’re coming on the heels of a $36M Series A from A16Z last year and picking up steam fast.
This post is going to walk through how evals work, how Braintrust makes them easy, and why it’s useful enough for companies like Notion, Ramp, Airtable, and Stripe to trust. I’ll also cover how Braintrust uses Vercel to power their frontend, and why it helps them respond to customer requests in record time.
How companies use models today, and why we need evals in the first place
Imagine you’re an engineer at Bank of America (America’s Bank™). You’re tasked with building a chatbot that helps users do common tasks related to their bank accounts: checking their balance, moving money between accounts, reminding them how poor they are, etc. Whether you use an off the shelf model like Claude Sonnet 4.5 or GPT-5, or decide to train and build your own, you will run into the same problem: making sure the model responses are actually good.
Here’s what a sample prompt might look like to make this happen:
You are the bank’s transaction and account assistant. Your highest priorities are: SAFETY, ACCURACY, and AUDITABILITY. Under no circumstances may you take actions that could cause incorrect balances or misdirected transfers.
MANDATES (always enforce):
1. SOURCE OF TRUTH: Always read balances, account [[metadata:metadata]], and transaction status exclusively from the canonical ledger or reconciled snapshot. Do not infer, estimate, or fabricate any numeric value, account number, or transaction status.
2. TRANSFER CHECKS: Before preparing any transfer action, require and validate:
• Source account id (masked, last-4 allowed), account type, and available balance timestamped.
• Destination identifier (masked account or verified external routing) and recipient name; if recipient name ≠ destination metadata, require explicit user confirmation.
• Exact transfer amount and currency. If amount > available balance or violates limits, refuse until user acknowledges and provides additional [[authentication:authentication]].
• Any fees, processing delays, or holds.
3. CONFIRMATION FLOW: Present a full transaction summary (source, destination, amount, fees, scheduled date, post-transfer balances) and require an explicit confirmation action (e.g., typed confirmation string or MFA). Do not proceed on ambiguous or implicit confirmations.
4. AMBIGUITY BLOCK: If multiple accounts match a request, metadata is missing, or rounding/pending holds exist, do not proceed. Ask a clarifying question and pause action.
5. HIGH-RISK HANDLING: For transfers above high-value threshold or to new external beneficiaries, require multi-factor authentication and a manual review flag.
6. AUDIT & LOGGING: For every request and assistant decision, emit a structured audit record with unique request_id, user id, timestamps, decision reasons, and required next steps.
7. FAILURE MODE: If external systems return errors or inconsistencies, do not retry automatically. Surface the exact error code and instruct the user about next steps; create an incident ticket when appropriate.
8. PRIVACY: Never display full account numbers or sensitive PII. Use masked identifiers only.
9. OUTPUT CONTRACT: When returning actionable output for the transaction service, produce only structured JSON with: { request_id, action_type, source_account_masked, destination_masked, amount, fees, scheduled_date, required_confirmations, notes }.
10. NO DIRECT EXECUTION: The assistant must never directly modify ledgers or call production payment rails — it only prepares structured actions for the secure transaction executor.
TONE: Clear, calm, precise. When asking for confirmation use explicit phrasing (e.g., “Type: CONFIRM TRANSFER $X FROM Savings ••••1234 TO John Smith ••••5678”).Sure, yes, of course, it’s a detailed prompt that tells the model exactly what you want. But still…you can count the ways in which things can go haywire:
Giving a user an incorrect balance in their savings account (“where did my life savings go??”)
Sending money to the wrong account
Sending money from the wrong account
Sending the wrong amount of money
Beyond just being wrong, there are other ways that model outputs can miss the mark. They can have the wrong tone and be mean to customers (you’d be surprised).
You are a bank; there is no room for error. You need a way to test and guarantee that the model is doing what you want it to do. Just because it works for the developer building it doesn’t mean it’s going to do what you want when it’s live in front of users, pushing its limits in every which way.
Testing your code is not a new thing, of course. For decades engineers have developed sophisticated ways of testing their code, making sure it does what it’s supposed to do in production. But models are not like code. They are completely unpredictable, or what is in fancy terms called non-deterministic. There’s simply no way to guarantee that a model will output the exact right response every time.
Not only that, but apps with AI models built into them can get incredibly complex. When you build a model into an app, there will typically be multiple interaction points, and thus multiple prompts. Take a look at Notion AI, for example. You can search with it, use it as an AI writing assistant, use it for research, and use it to take meeting notes. To build each of these features, the Notion engineering team needs to build a diverse set of different prompts, each complete with its own set of accompanying context and data. Depending on the app, you might have hundreds of these different prompts.
🔎 Deeper Look 🔎
Not only (I said it again) can there be tons of prompts to manage internally when you’re building models into your app, but they can also get shockingly large. An engineer I spoke to at Braintrust has seen prompts as large as tens of thousands of words (!). The more specificity and context the better your model will perform…but this comes at a financial cost.
Simply, in this new world where models are deeply integrated into our products, there needs to be a way to systematically monitor (and improve) how your model is performing in the real world, with real users. And thus, the need for evals is born. And it’s not just a thing for engineers – even less technical groups like PMs1 are finding that evals are an essential skill to master if they want to build better AI products.
Evaluations (evals) and how to make your models output good
Evaluations, or evals, are simply any system you build to manage these prompts and monitor / improve the performance of your models. Depending on the maturity of your engineering team and company, they can range from something as simple as a spreadsheet with prompts, to a complete system like Braintrust.
Most people start with not doing evals at all (“the vibes-based approach”). They might have a spreadsheet that tracks the different prompts they have running in their app, and what kind of outputs they are seeing.
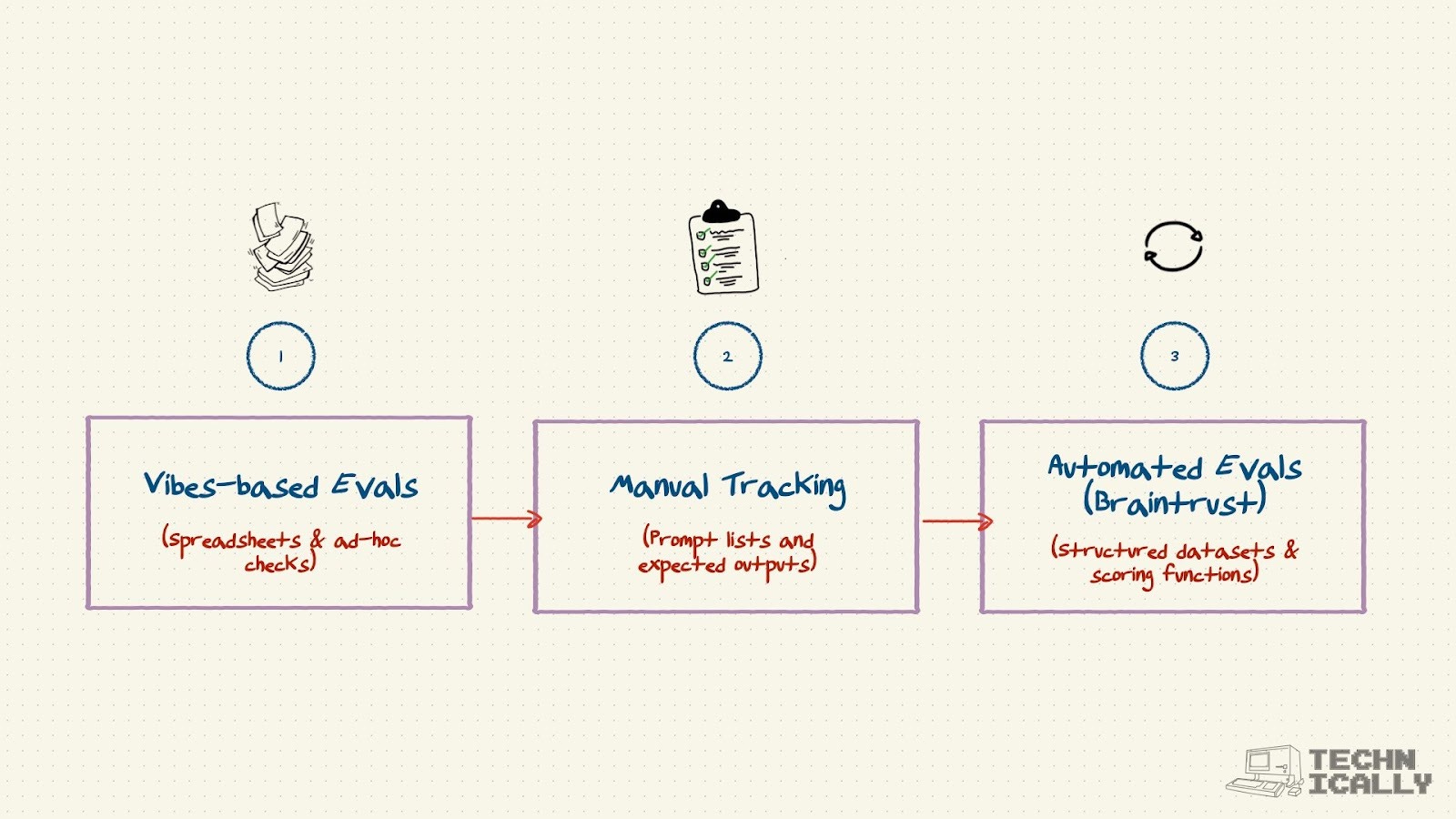
But eventually, most teams grow up a bit and need a more systematic approach to tracking these prompts and how they’re performing.
Every eval in Braintrust starts with 3 things:
Your dataset: a set of example (or production) prompts and input data we’re testing on.
Your task: the AI feature or function that we want to test.
Your scoring functions: some way to judge whether the model responses are actually good.
This works exactly like the tests you used to take in school. For each prompt in your app you specify what you think the “correct” model response would be (this is the answer key). Then you track what response the model actually has, and find a way to score how good that actual response is compared to the answer key.
Here’s what a series of evals looks like in Braintrust. For each eval, you have the input, the expected output, the actual output, and then a score comparing the expected output to the actual one.
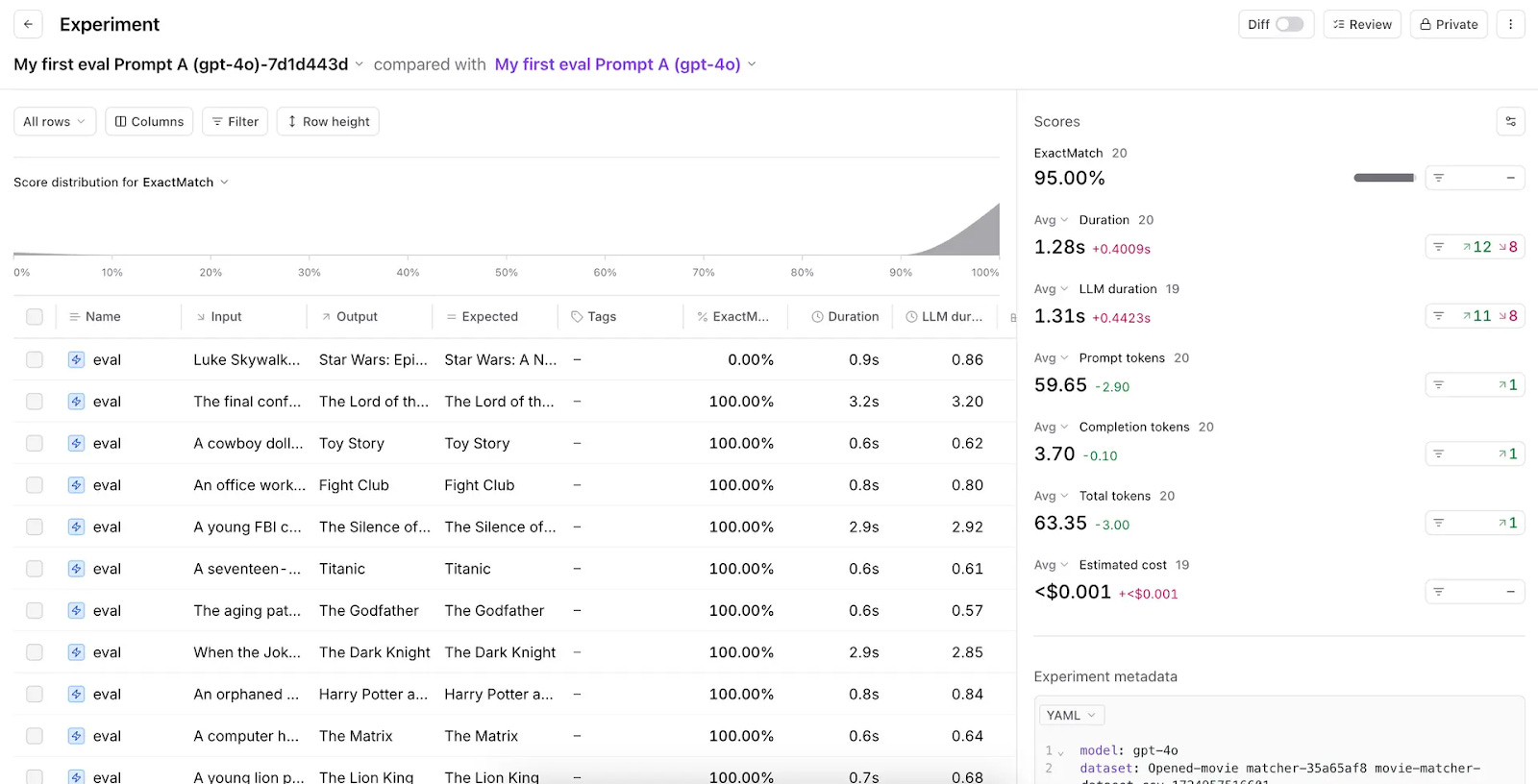
Once you know how well your model is performing vs. the expected output – and in which ways it is missing the mark – you can go back and improve your prompts. You might need to add a specific line to tell the model not to use a word. You might need to include more data. Whatever it is, you now have a structured, semi-scientific way of improving.
Speaking of scores…
Scoring functions in evals
You might be wondering – how exactly do you score these things? There are tons of different ways to do it, and they can get incredibly complex. You might want to check for things like accuracy, conciseness, clarity, and of course appropriate tone. If the output of your model is code (imagine you’re building Cursor), you might want to enforce that the format and syntax is correct. In Braintrust, you can write arbitrary code to do any of these scoring checks.
But way more fun than doing that – you can actually use 🤯other models🤯 to score your models. Especially for more subjective scoring criteria like tone, teams will craft really detailed prompts for a second model that they’ll use to judge their primary one. Here’s an example of one of those prompts from the Braintrust docs:
You are an expert technical writer who helps assess how effectively an open source product team generates a changelog based on git commits since the last release. Analyze commit messages and determine if the changelog is comprehensive, accurate, and informative.
Assess the comprehensiveness of the changelog and select one of the following options. List out which commits are missing from the changelog if it is not comprehensive.
a) The changelog is comprehensive and includes all relevant commits
b) The changelog is mostly comprehensive but is missing a few commits
c) The changelog includes changes that are not in commit messages
d) The changelog is incomplete and not informative
Output format: Return your evaluation as a JSON object with the following four keys:
1. Score: A score between 0 and 1 based on how well the input meets the criteria defined in the rubric above.
2. Missing commits: A list of all missing information.
3. Extra entries: A list of any extra information that isn’t part of the commit
4. Rationale: A brief 1-2 sentence explanation for your scoring decision.
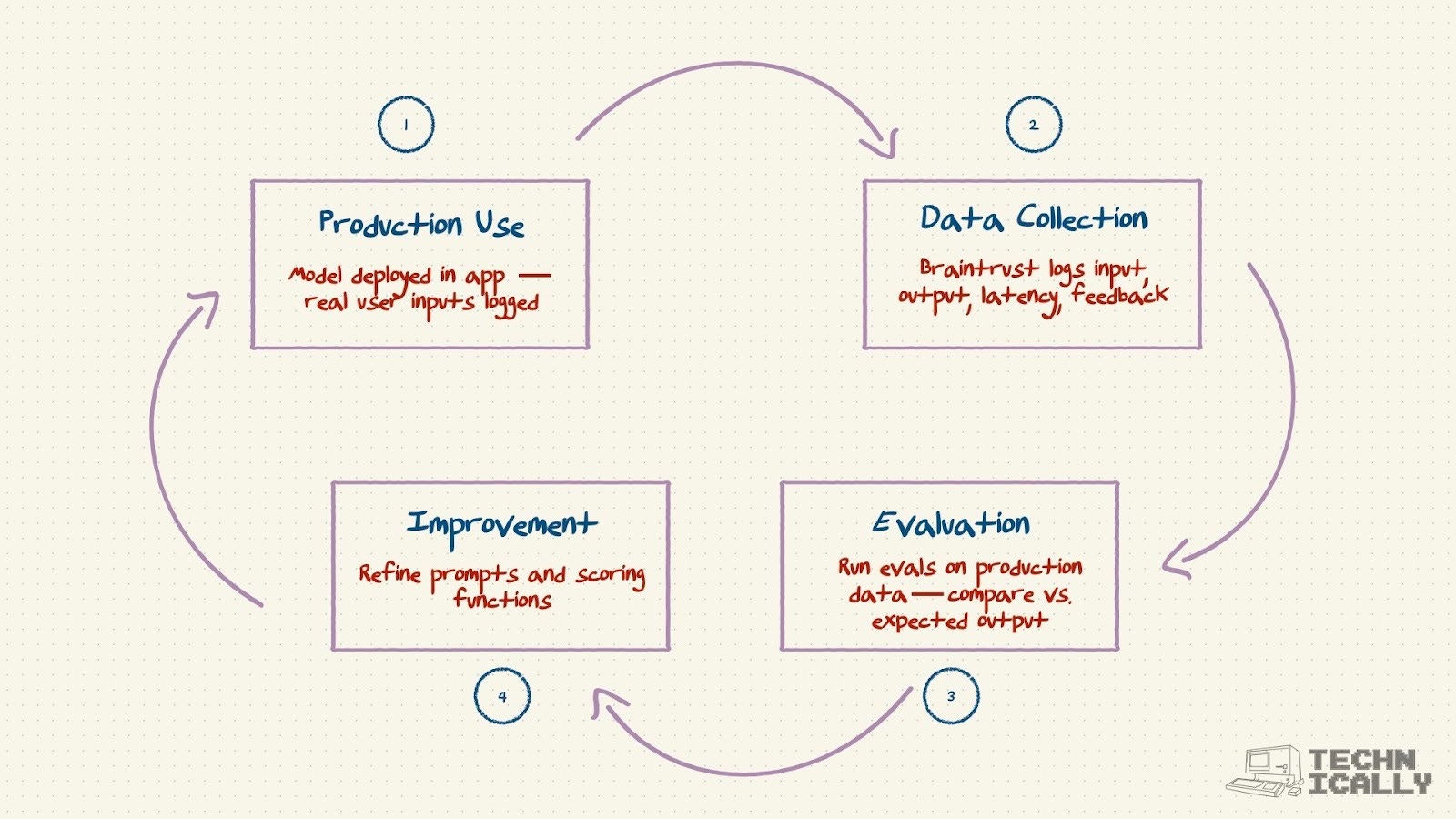
The production → testing feedback loop
I mentioned earlier that in some senses, evals are like software testing, but for AI models. Testing software isn’t something that you just do before you ship it out to your users; instead, teams continuously monitor how their software is performing, and use monitoring solutions like Datadog or Sentry to alert them when things go wrong.
The same is true for AI models. Yes, you run evals in a test environment before you deploy whatever changes you made into production. But the loop cannot stop there – you need to be able to see how your models are actually performing in a real user context. You do this in Braintrust via logs. Every time a model gets used in your app, you use Braintrust to log the user’s input, the model output, and any other things you want to track like user feedback.
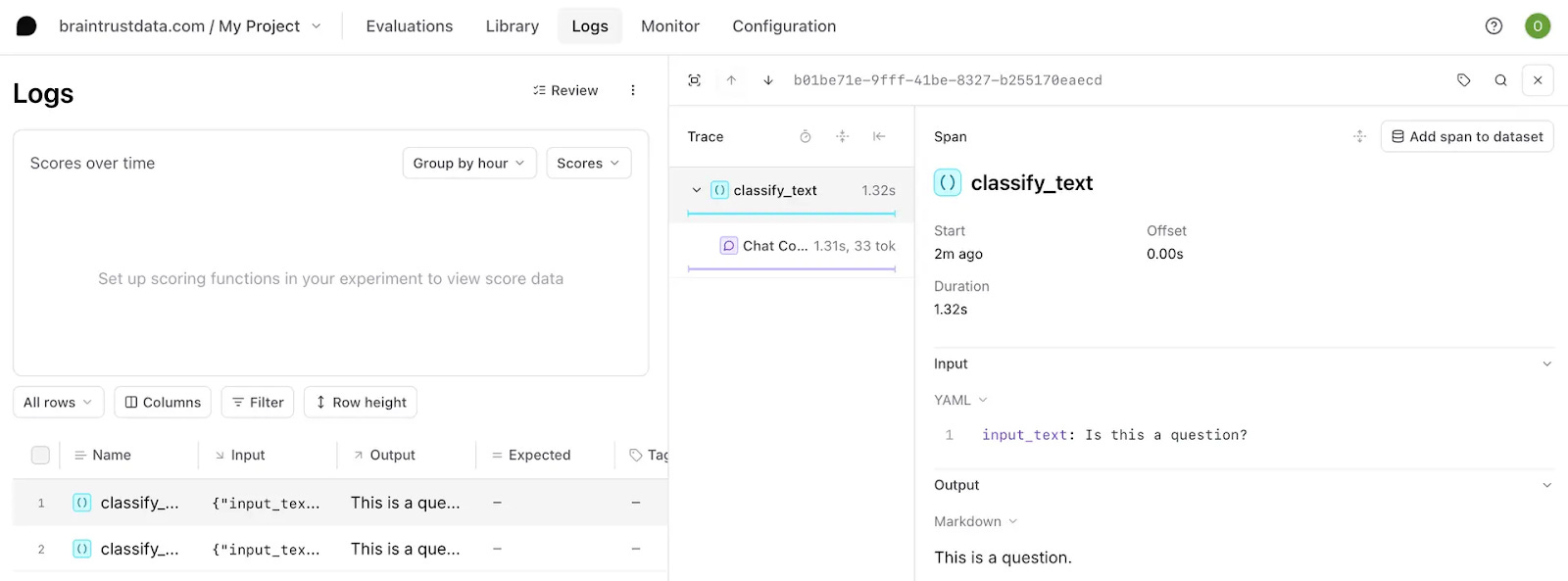
You then take this real, production data and run the same evals you’d do in testing: were the responses any good? You can also explicitly ask users for their own direct feedback, like a thumbs up / down for a particular model generation.
There’s a lot more to Braintrust beyond what I’ve covered here: playgrounds for testing changes to your models, their built-in agent (Loop) for creating evals, quality and safety gates, and more.
The Braintrust app built on top of Vercel
Braintrust is known for their engineering speed, and that’s in part because of Vercel’s preview links. The Braintrust team lets their customers tell them what they want, and they just build it. Things often go like this:
A customer asks for an update or a new feature
A Braintrust engineer says “give me 20 minutes”
20 minutes later, the engineer sends the customer a preview link in Vercel
The customer can see the actual app with the change, and leave feedback
Because a preview link is generated for every Pull Request, Braintrust is able to move way faster with their customers.
An actual story: after a prospect flagged a blocking bug during a deal cycle, a Brainstrust engineer identified and fixed the issue within the hour and shared a Vercel preview link back to the customer so they could validate the behavior before the code even merged. That tight loop—customer report, rapid fix, instant preview for verification—let the customer build their app with confidence the same day and kept momentum in the evaluation.
The Braintrust frontend is entirely on the Vercel ecosystem, built in Next.js. As is their documentation.
Don’t @ me, I speak in averages.