

Technically Monthly (November 2025)
How machines learn from data, what happens after you vibe code an app, and how to build AI products that don't embarrass you in production.


Hello distinguished Technically readers,
Technically Monthly returns with a deep dive into the fundamentals — how machines actually learn, what happens after you vibe code an app, and how companies keep their AI from embarrassing them in production.
Plus, a long-awaited update on one of our favorite developer tools: Vercel.
Here’s what’s new in Technically knowledge bases:
New on Technically
What is Machine Learning?
Available as a paid preview on Substack, and now in its permanent home in the AI, it’s not that complicated knowledge base.
Just like me, Machine Learning has been around since the 1950s and is actually simpler than you think: data has patterns, and you can use those patterns to predict what happens next.
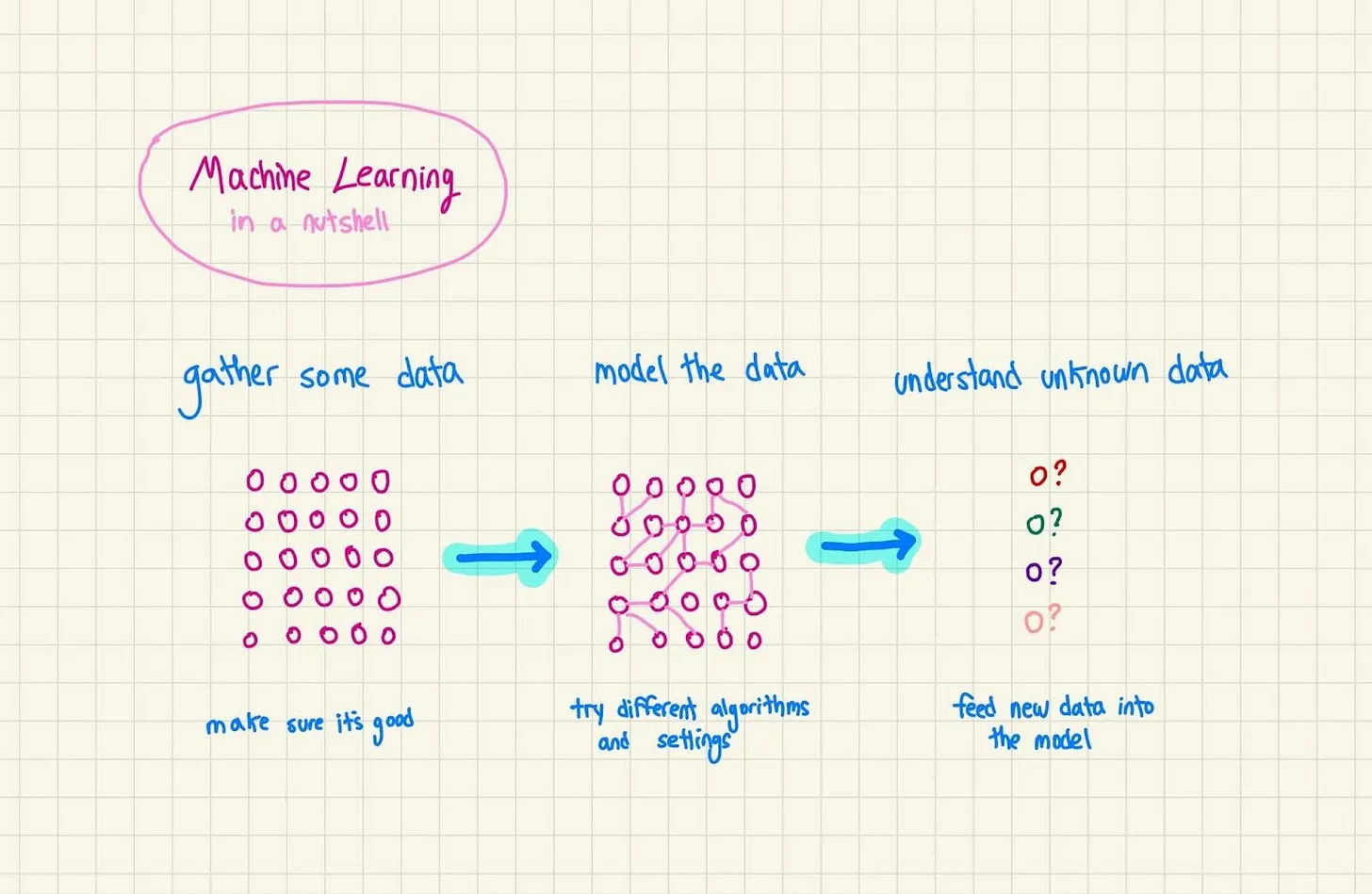
This post explains:
The three-step ML process: curate data, train the model, predict outcomes
How to frame problems as ML problems (including that delightful corn pest example)
Supervised vs. unsupervised learning, and what reinforcement learning is all about
Common algorithms from linear regression to the neural networks that power ChatGPT
The vibe coder’s guide to real coding
One of three sponsored posts made free this month, courtesy of Vercel, available as a free post on Substack and in the AI, it’s not that complicated knowledge base.
Vibe coding is great, because now you can build the app of your dreams after being relegated to “the business side” for years. But do you really understand what’s going on under the hood? And do you know how to make sure your app actually works in the real world?
This post walks through the 5 basic things vibe coders need to know about their apps:
Servers and the cloud: where your app lives and how to deploy it properly
Backends 101: databases, APIs, authentication, and why they matter more than you think
Version control with Git: how to make changes without breaking everything
Monitoring: making sure your app is fast and bug-free
Security basics: or, how not to get absolutely destroyed by hackers
Whether you use v0, Replit, or just regular old ChatGPT, this guide gets you from “I made a thing” to “I made a thing that won’t embarrass me.”
How Vercel became the frontend AI cloud
Part of this month’s Vercel-sponsored for their Ship AI conference, available as a free post on Substack.
A few years ago, Vercel was laser-focused on one thing: making it stupid easy to deploy your frontend. But then AI happened, and they’ve since done incredible work helping developers build AI into their products.
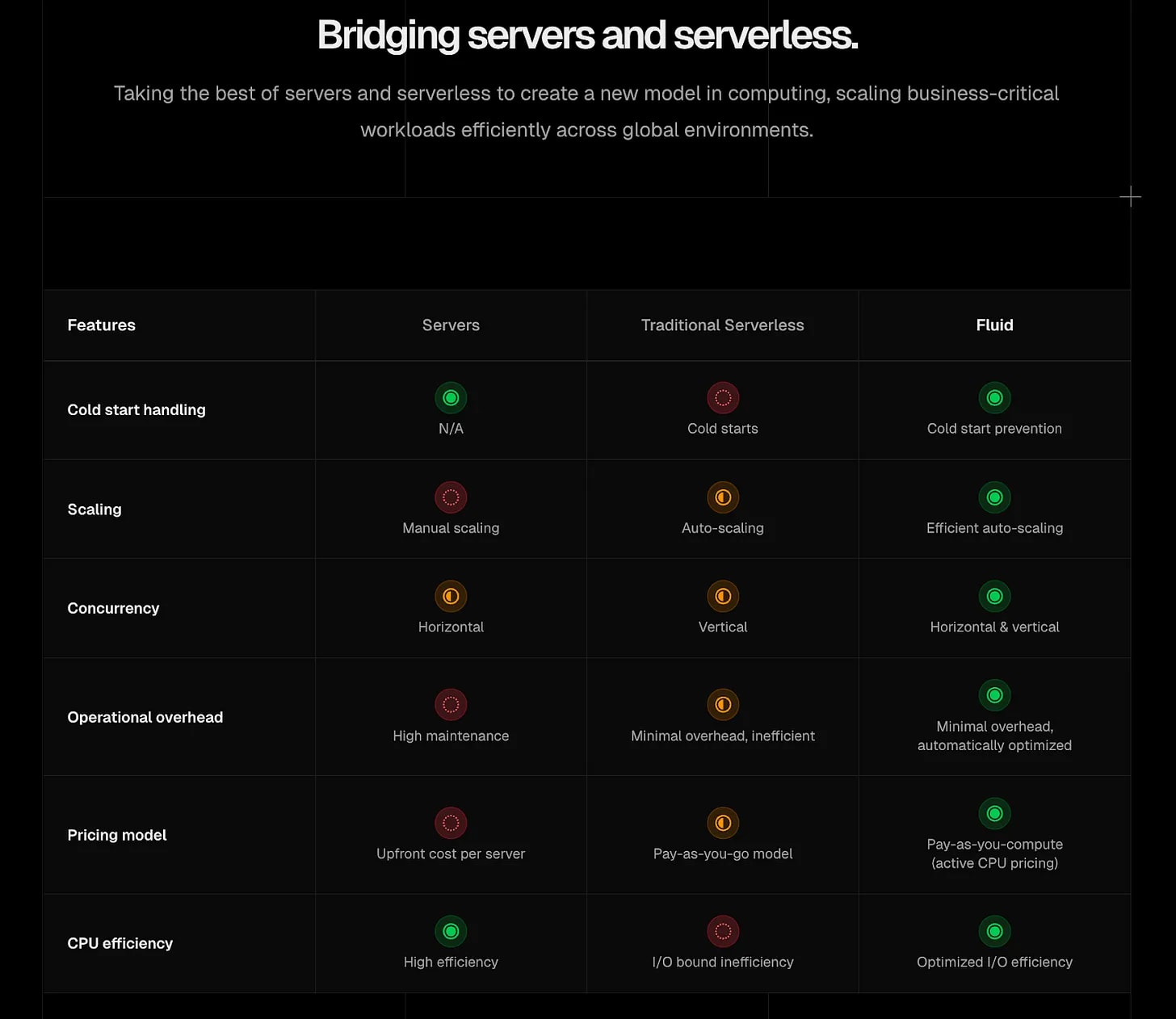
This post covers:
Why building AI into apps is harder than it looks
The AI SDK: write once, swap models easily, no Noah’s Ark situation required
The AI Gateway: switch models and manage spend without rewriting code
Fluid Compute and Sandboxes: infrastructure that actually works for AI’s weird requirements
If you’re building AI into your product and fighting the tide, this post is for you.
How to build AI products that are actually good
The third in this month’s series of Vercel-sponsored posts, free on Substack and available in the AI, it’s not that complicated knowledge base.
Imagine you’re Bank of America, building a chatbot to help users check balances and move money. You write a detailed prompt. It works great in testing. You ship it. Then it sends someone’s rent payment to the wrong account.
This exact situation is why you need evaluations, or evals – systematic ways of testing your AI models. This post covers:
Why you can’t just “prompt and hope” when millions of users are involved
What evals are: systematic testing for AI models using datasets, tasks, and scoring functions
How Braintrust makes evals easy (and how they use other models to score your models 🤯), and how they use Vercel to iterate quickly on their product
If you’re building AI products at scale, evals aren’t optional. They’re the difference between “it works for me” and “it works for everyone.”
From the Universe: the Loss Function
When training a machine learning model, a loss function is something you design that tells the model when its answers are right and when they’re wrong. There are a bunch of different types, some catered to specific ML tasks like image classification (whether a plant has a bug on it or not) or regression (predicting a stock price), or predicting the next word in a sentence for an LLM.
As a model is trained, it predicts an answer to a question. If it’s right, it gets a point. If it’s wrong, it loses a point. After enough of these iterations, it starts to learn how to predict the correct answer.
There are lots of different types of loss functions, but behind the scenes, they’re just telling your model “good job” or “try again.” This is why it’s so important, when training an ML or AI model, to have nicely curated, labeled data with a clear right and wrong answer.
Coming up this month
We’ve got two posts on deck for November, with potentially a third surprise post if the stars line up:
A vibe coding tool bake-off: which vibe coding tool is right for you? We review Replit, v0, Lovable and Bolt, to see who will be Vandelay Industries preferred vibe coding tool.
What’s RLHF? Reinforcement learning is the technique that allows AI models to actually be helpful, rather than the weird early versions of GPT that everyone laughed at.
Are you using AI at work?
We’re continuing to dig into how people are actually using AI tools day-to-day. Built a clever workflow? Vibe coded something impressive? Got your team hooked on Claude? We want to hear about it — just respond to this email.